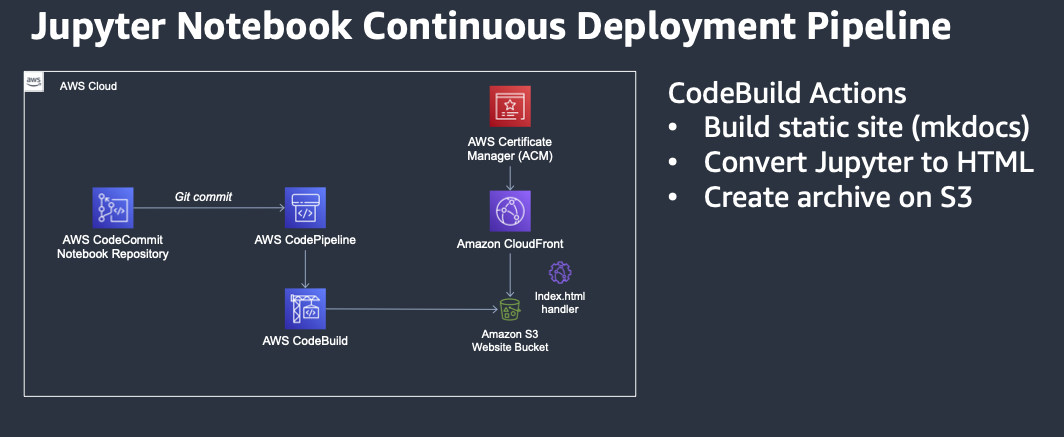
Vibe Coding Rust CLIs
This holiday break, I’ve been working on an arcane side project of resurrecting historical versions of my blog from 2002. As part of this, I’ve been digging around various S3 buckets for backups of old source code and mysql dumps. But doing so in the AWS console is not the most ergonomic, so I wanted to (have AI) whip up a quick terminal UI that could make it easier. I’ve done this a couple times now, first with s3grep, and somebody suggested it might be good to document my journey so here we go! ...