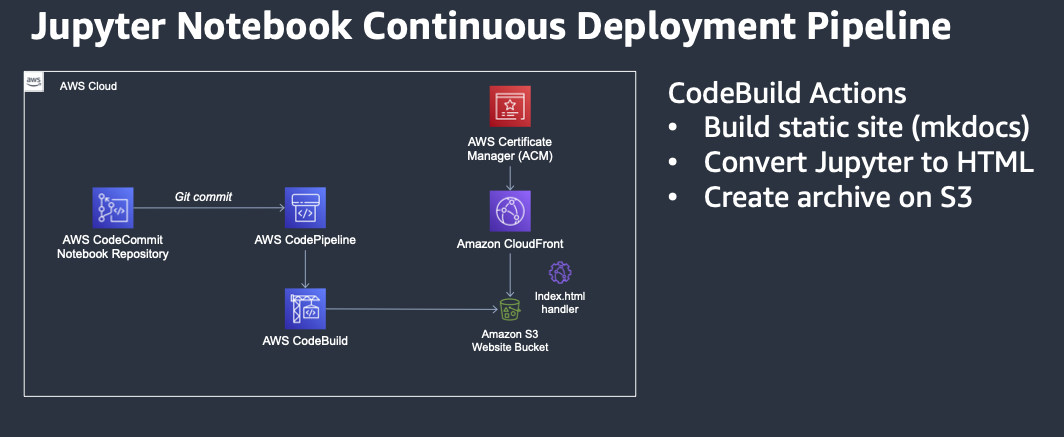
"Serverless" Analytics of Twitter Data with MSK Connect and Athena
Like many, I was recently drawn in to a simple word game by the name of “Wordle”. Also, like many I wanted to dive into the analytics of all the yellow, green, and white-or-black-depending-on-your-dark-mode blocks. While you can easily query tweet volume using the Twitter API, I wanted to dig deeper. And the tweets were growing… Given the recent announcement of MSK Connect, I wanted to see if I could easily consume the Twitter Stream into S3 and query the data with Athena. So I looked around a bit and found this kafka-connect-twitter GitHub repo and this great blog post from Confluent on analyzing Twitter data using that connector. So…off to the AWS console! ...